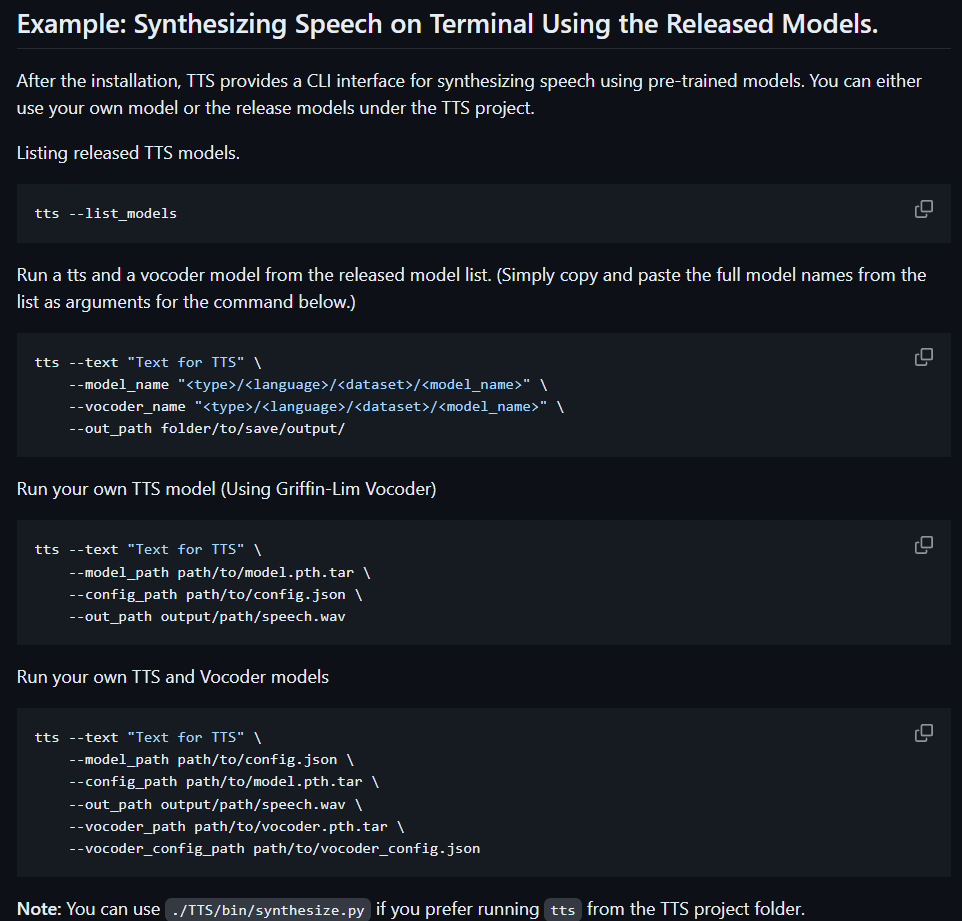
TTS

Mozilla TTS (Text-to-Speech) - это проект на GitHub, разработанный Mozilla, который представляет собой систему генерации речи на основе текста с использованием искусственного интеллекта. Вот некоторые из плюсов и минусов этого проекта, а также как он работает в связке с изображениями:
Плюсы Mozilla TTS:
1. Открытый исходный код: Mozilla TTS доступен как проект с открытым исходным кодом на GitHub, что позволяет разработчикам изучать, модифицировать и улучшать его.
2. Высокое качество речи: Mozilla TTS предоставляет возможность генерации речи высокого качества с естественным звучанием.
3. Многоязычная поддержка: Проект поддерживает генерацию речи на нескольких языках, что делает его универсальным для широкого круга пользователей.
Минусы Mozilla TTS:
1. Требовательность к вычислительным ресурсам: Mozilla TTS может потребовать значительных вычислительных ресурсов для обучения и работы с моделью в реальном времени.
2. Сложность в настройке: Настройка Mozilla TTS и обучение модели может потребовать определенных знаний и навыков в области машинного обучения.
Как работает Mozilla TTS с изображениями:
Хотя Mozilla TTS изначально разработан для генерации речи на основе текста, существует также возможность использовать изображения для управления процессом синтеза речи. Например, изображение с текстовой информацией о дне недели и погоде может быть использовано для синтеза речи, предсказывающей прогноз погоды на указанный день.
Процесс работы Mozilla TTS с изображениями может выглядеть следующим образом:
1. Использование изображения в качестве входных данных: Изображение, содержащее контекст для генерации речи, подается на вход модели Mozilla TTS вместо или в дополнение к текстовому описанию.
2. Обработка изображения: Исходное изображение анализируется и извлекаются признаки, которые могут быть использованы моделью для генерации речи.
3. Синтез речи: На основе анализа изображения и с использованием модели ML происходит синтез речи, выполняющий обращение к визуальным данным и генерирующий соответствующий аудиоконтент.
Таким образом, использование изображений в Mozilla TTS позволяет расширить его функциональность и применять для различных задач, связанных с генерацией речи на основе информации, содержащейся на изображениях.
.png)