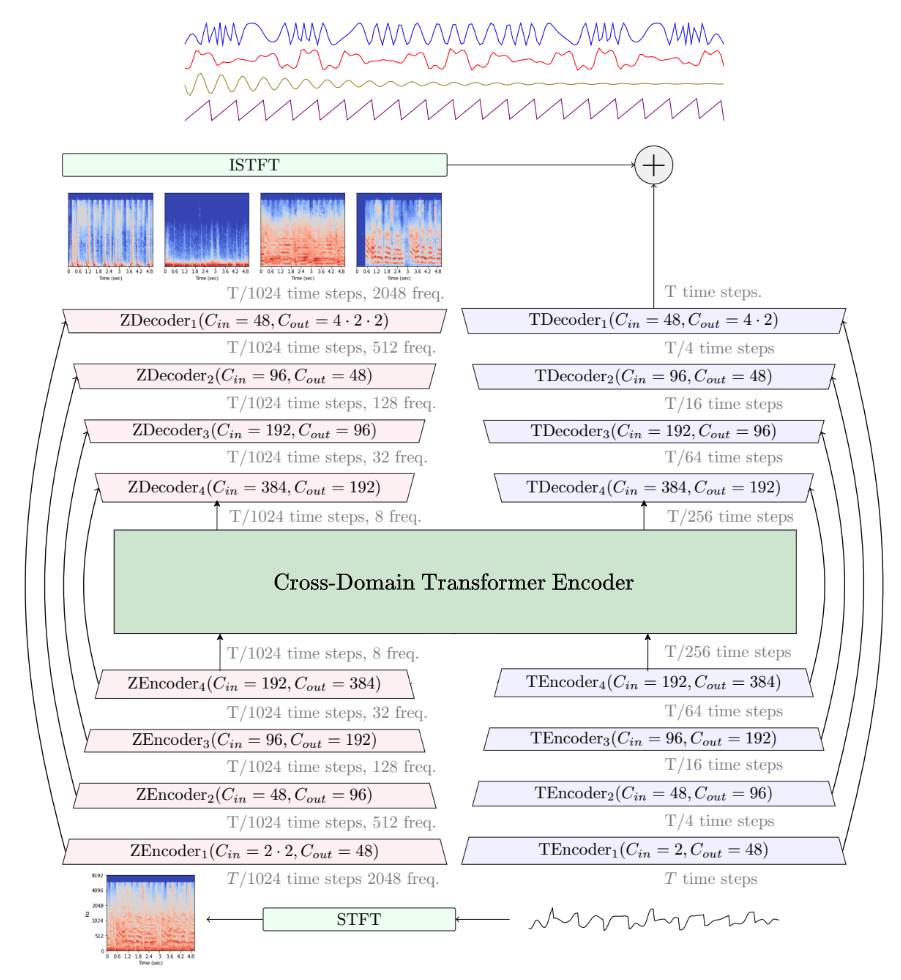
Demucs
Demucs (Deep Extractor for Music Sources) — это модель машинного обучения, разработанная для задачи разделения музыкальных треков на отдельные компоненты, такие как вокал, барабаны, бас и другие инструменты. Эта технология основана на глубоких нейронных сетях и использует сложные архитектуры для точного извлечения отдельных аудиодорожек из смешанных музыкальных композиций.
Принцип работы
Demucs использует подход с свёрточными нейронными сетями (CNN) и рекуррентными нейронными сетями (RNN), чтобы выделить различные аудиокомпоненты. Основные этапы работы модели включают следующие шаги:
- Предобработка данных: Аудиоданные разбиваются на небольшие фрагменты.
- Обработка нейронными сетями: Каждый фрагмент обрабатывается с использованием спектрограмм, которые представляют аудиоданные в виде частотных компонентов. Эти спектрограммы передаются через сложные слои нейронной сети.
- Подсчет и обратное преобразование: Модель предсказывает отдельные компоненты, после чего производится обратное преобразование спектрограммы в аудиосигнал.
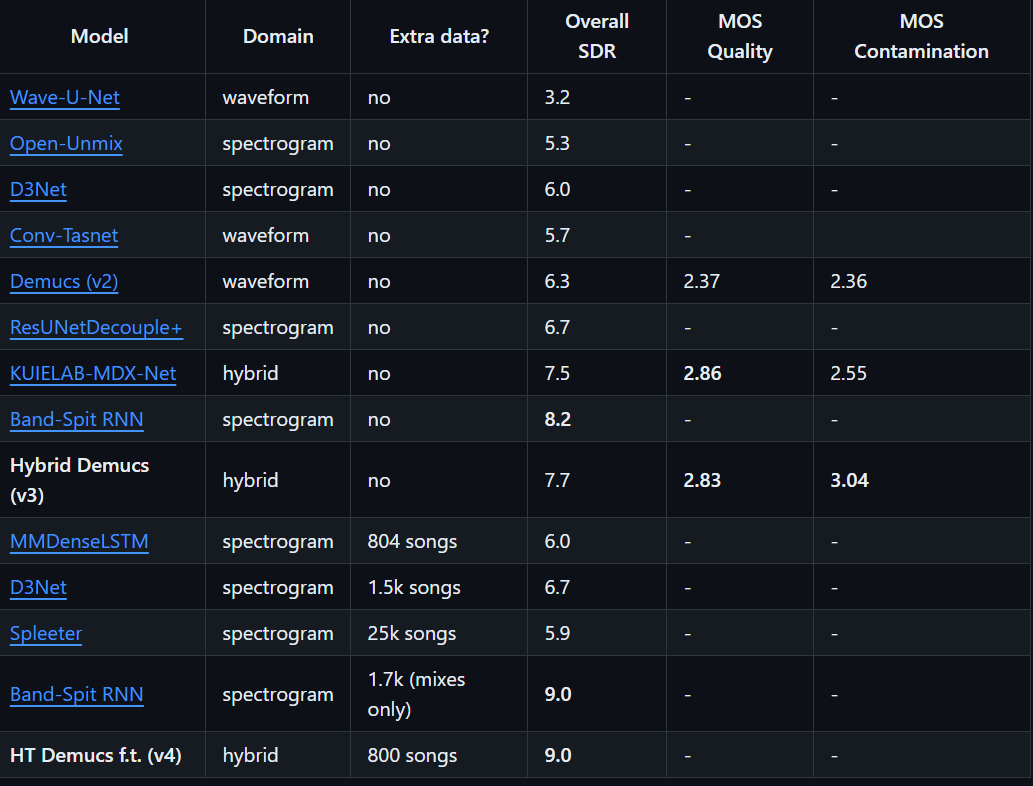
Плюсы
- Высокая точность: Современные модели, такие как Demucs, достигают высокой точности при разделении сложных музыкальных композиций.
- Широкий спектр применения: Модель может быть использована для ремиксов, караоке, улучшения качества звука и анализа музыки.
- Гибкость: Модель может быть дообучена на специализированных наборах данных для улучшения качества разделения определённых жанров музыки.
- Автоматизация: Сокращает потребность в ручном редактировании треков для разделения компонентов.
Минусы
- Высокие вычислительные затраты: Обучение и выполнение анализа требуют значительных вычислительных ресурсов, включая мощные GPU.
- Невозможность полного разделения: В некоторых случаях разделение компонентов может быть неточным, особенно если инструменты или вокал накладываются друг на друга по частотам.
- Подверженность к шумам: При наличии шума в исходном аудиофайле модель может ошибаться, выделяя нежелательные компоненты.
- Ограничение по обучающим данным: Качество результатов может сильно зависеть от данных, на которых была обучена модель. Неподходящие или неполные наборы данных могут ухудшить производительность.
Заключение
Demucs представляет собой современный подход к задаче разделения музыкальных треков, предлагая высокую точность и широкие возможности для применения, несмотря на некоторые ограничения и вычислительные затраты. Эта технология является важным инструментом для музыкальных продюсеров, исследователей и энтузиастов, стремящихся к лучшему пониманию и манипуляции аудиоматериалов.